The Internet Is ForeverPart I: Free Internet ServicesPrivacy and InternetThe Economics of PrivacyGDBRData BreachesPrivacy and the Big BrotherInternet Privacy is an OxymoronSafekeeping of Digital Assets Is Very HardBrave's BAT (Basic Attention Tokens)Life After Google: Ten LawsPART II: Cyber Realities and Attack SurfacesPart III: Private Security Through Ai-FiPart IV: Ai-Fi Security FrameworkIntroductionPseudonymous Ai-Fi IDCreating Your Ai-Fi AccountThe Zero-Knowledge DoctrineHow Much Does Ai-Fi.net Collect about a DomainKnown to Ai-Fi.netNot Known to Ai-Fi.netMeta-Data and YouSecurity by DesignMulti-Tenant Configuration CacheHierarchy of OwnershipRemedy for Losing Your Ai-Fi Account Identification CellphoneAi-Fi Support for Internet Browsing and TorBranch Start-Up and AuthenticationPart V: Extending The TLSAsynchronous Session and Future SecrecyAi-Fi SecureEmailReferences
The Internet Is Forever
This is a write-up discussing the modern day security and privacy concerns for people who surf the Internet. It describes the many layers of service structures over and above the ISPs' (Internet Service Providers) which only provides the data transport without peeking into the content of passing traffic. The repeal of "net neutrality" and the increasingly popular "Snoopers' Charter" may change this layering somewhat, but the basic architecture and its security implications will remain the same.
The focus is on matters involving both the data traffic which carries content and the "metadata" which provides information about one or more aspects of the underlying data. The issues analyzed are anonymity, privacy, and measures against surveillance, which are confronting all of us in this day and age. We conclude the discussion by describing how Ai-Fi.net can be an effective infrastructure for answering most of these concerns.
Part I: Free Internet Services
Privacy and Internet
Throughout human history the advent of new communication technologies has had a dramatic impact on our cultures. The invention of language, writing, printing press and the electronic media of radio and television are all breakthroughs that draw mankind further together. Those advances in communication transform humans into a true worldly species with shared views and consistent vision of the world based on publications, news, science, recorded histories, and the interchange of products. In parallel with the development of print and broadcast media are the telephones, which in present-day nomenclature are P2P (Peer to Peer) media that, unlike others, were offered to us as a public utility and not a monopolized service by private enterprises.
Post the Industrial Revolution the Internet descended on us as the next decisive technology of the Digital Age, and with the explosion of wireless communication humankind is now entirely connected at the speed of light. However, in this Internet age we are confronted with an unprecedented challenge; never before the ruling technologies of the day are so tightly controlled in the hands of so few:
- The Internet landscape is mapped by search engines, run by a very limited few like Google, Baidu, Bing, and a very few others.
- The social media where we congregate on the Internet are dominated by Facebook, WeChat, VKontakte, et cetera.
- The Internet commerce sites are dominated by Amazon, Alibaba, et cetera.
In other words, our view of the world, our social interactions and our consumptions conducted on the net are all controlled by a very small number of corporations. It would be inconceivable if the Library of Congress is run by a private enterprise, and yet we negotiate our way around the Internet almost exclusively through Google, Facebook, WeChat, Baidu and other search engines and social media. The most chilling aspect of these new Internet phenomena is that these searches and social activities are conducted under ever-present watchful eyes, with all our movements and footprints recordable by these service "platform" providers of practically unlimited resources. The elephant in the room is obviously the fact that all these new Internet powerhouses are for-profit enterprises offering "free" access to digital goods and services, including most importantly the information about the world and our intimate social contacts. In this exchange for "free" services, we the consumers are at a distinct disadvantage. We mindlessly surrender our privacy, which is the currency of all these "free" Internet services, without an inkling of how these data on our private life are packaged, warehoused and ultimately auctioned off. Worse yet, we have zero say in this transaction, the monetization of OUR own privacy. We are irrevocably trapped in this giant spider web of "free" Internet by monsters of enormous size and power incomprehensible and impenetrable to us.

The Economics of Privacy
Privacy, economics, and technology are inextricably linked: individuals want to avoid the misuse of the information they pass along to others, but they also want to share enough information to achieve satisfactory interactions; organizations want to know more about the parties with which they interact, but they do not want to alienate them with policies deemed as intrusive. However, there is a vast disparity of resources available for handling the privacy matters between the individuals and the big corporations behind the electronic transactions. The insidious nature of the possible privacy infringement is such that the majority of us do not even recognize the threat. As technology of big data marches forward, fueled by the ever widening data collection on us by the likes of Google and Facebook, the impact of our casual online activities on our privacy is grossly underestimated by us. For instance, we rarely consider an occasional upload of our face or birthday party pictures of our children as potentially harmful, which is what we typically send to Facebook voluntarily anyway, until many of us are shocked in discovering the following unintended consequence:

A single innocent photo of us can be linked to our name, our birthday and our Social Security number, 27% of the time. This experiment was carried out and confirmed as early as in 2005. Now in 2018, 13 years later, the hit rate is most likely approaching 100%. The Social Security number in turn leads to our financial identity, our credit report, our home mortgages, our car loans, our tax records, credit cards and many other information we unquestionably consider as "must protect" in order to avoid the much feared identity theft and online fraud. This is not even counting the fact that Social Security is firmly in the hands of our government. However, we routinely carry out this upload carelessly.
People uploading innocuous photos of themselves are actually feeding additional training material and updates to invisible intelligent facial recognition bots in the background to pinpoint them more accurately. Mark Zuckerberg called those people "dumb fucks" when he was a 19-year-old. Both "Zuck" and those dumb fucks haven't changed much since .
Intelligent software has been successful in extracting a few photos from our Facebook pages about our children or best friends, and putting together a composite image masquerading as a spokesperson for certain merchandise with all the friendly features extracted from those publicly available photos we voluntarily submitted. Most of us will find that composite spokesperson's face strangely likeable and therefore powerfully suggestive in influencing our buying decisions.
The following is a photo collection of attractive people:

Most of us fail to realize that these are computer-generated fake images. Ask yourself which one of these fake people you'd like to have for your date or salesperson? Well, don't strain yourself. Facebook will happily customize one for you. All you need to do is to upload your recent photo, your family pictures, your party snapshots, your birthdays, your outings and travels, your engagement and weddings, et cetera., so Facebook can use them to "train" its artificially intelligent "bots" in the cloud to generate them for you to your specification. Actually, come to think of it, you don't even need to upload them. Facebook already has all the necessary ingredients from your past uploads. There is no shortage of "dumb fucks".
Our search for a job in this Information age faces new challenges as well. Job applicants used to be in control of the information they wanted to reveal to the hiring party. This is unfortunately no longer the case. Many job candidates nowadays unknowingly provide personal information through social-network profiles, including information such as age, race, sexual orientation or religious affiliation, which may be actually protected under state or federal laws. Employers are not supposed to ask about such information during the hiring process but searching for it online significantly reduces the risk of their being detected. Researches indeed uncovered evidence of both search and discrimination among many employers.
None of us just share our lonesome personal portraits on Facebook. The photographs we upload to social media are mostly about events and relationships, of which the location, time and people involved are all recorded, uploaded and published. Those photos we submit and publish contain privacy data regarding others as well. The research project Creepic conducted at UC Santa Barbara[PhotoAnalysis] successfully combines facial recognition, spatial analysis, and machine learning techniques to determine pairs that are dating or engaging in intimate relationships. More alarmingly, even if an individual decides to avoid social networks altogether, their privacy can still be invaded. Unless they forbid their friends from taking any pictures of them at all and manage to enforce this anti-social behavior as a personal crusade, analysis of their social behavior could still be carried out based on photographs uploaded by their friends. There is no easy escape from this collateral damage inflicted by others under the current social climate.
This is just a sample list of faceless technologies which lock on us squarely with their crosshairs. We hope that you've somewhat convinced that the paranoid attitude towards privacy by some of us is not as unjustified as you might have thought. In less than ten years the likes of Facebook and Google have assembled an immense collection of data on each of us. Any move you make and any step you take on the net is no longer an isolated happenstance. A simple innocent photo we post, the coordinate of our whereabouts, the gazing street CCTV camera we saunter by and other casual acts of ours are no longer inconsequential. They will all be compiled into an intricate web of details profiling our singular life for the undying future without our awareness or consent. We are no longer in possession of our own identity. Worse yet, we frequently become an unintended target as the collateral damage from decisions other people make. Facebook collects data from people online even if they don't have a Facebook account. There are "shadow profiles" collected on you from places you'd never have imagined.
GDBR
Regardless of how rigorous the GDPR (General Data Protection Regulation) rules appear to be or how easy they are to be "understood as mandated", our records indicate that prior to GDPR, Google actually had a set of nicely written privacy statements (of 10 pages or so ?). After GDPR, the number of pages ballooned to more than 20, not counting the offshoots hyperlinked to from the main pages. Let's continue our threads on composite images or fake images. Google has a section titled "How Google uses pattern recognition to make sense of images", in which it is stated that:
"If you get a little more advanced, the same pattern recognition technology that powers face detection can help a computer to understand characteristics of the face it has detected. .... Similar technology also powers the face grouping feature available in Google Photos in certain countries, which helps computers detect similar faces and group them together, making it easier for users to search and manage their photos. "
In other words, the technology is ready, operational and applicable to all the photos you surrendered voluntarily to Google or Facebook. Under GDPR, Google may no longer be able to manipulate these data as arbitrarily as before. However, there are several gaping holes in this laws of 55,000 words[loopholes], primarily due to the escape routes made available during the transference of data to others, which potentially creates an invisible data chain with personal data held several steps removed from the data subjects after they are bought and sold like any commodity. Another major issue is the "inferred" information derived from the original data after combining with other sources by the "overseer" who may in turn refuse to provide a copy of the transformed data. These loopholes are always available to the overseers of your private data regardless if you actually read their GDPR statements or not. To read all the privacy policies you encounter in a year, it would take 76 work days.[FTC-new]
Privacy data are the currency and the sustenance those "free" services gorge on. Realistically, we as individuals don't stand a chance in fighting against those gigantic corporations, which continue to evolve and amalgamate among themselves into something even more sophisticated and aggressive[FacebookShared]. We are eons behind them technologically. It is a losing battle as long as we allow them to hold critical digital data on us, which lives on forever and is shared by those nameless big corporations. GDBR is irrelevant once the Genie is out of the bottle.
Data Breaches
The worst is yet to come if this trend of centralized surveillance capitalism persists, with or without GDBR. The not so subtle profit making practices of Facebook, Yahoo, Google, Amazon and Apple may not be directly equated to wickedness, but the following breaches are nothing short of evil. They are direct, malicious and blatant attacks on our privacy with clear criminal intent:
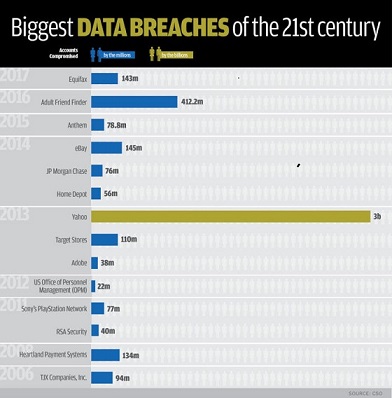
These cyber breaches and attacks are structural and systemic, showing no signs of abating. The likelihood of our being included in those stolen data directly or indirectly is difficult to assess and clearly would never be made completely known to us. Given the size and frequency of those disasters and the public nature of the disclosure, the risk to us individually is certainly quite considerable. There are reasons to believe this is just the tip of the iceberg as the size of those breaches is based only on detected or traceable evidence of covert access to digital assets, which understandably reflects only a fraction of the damages being published. According to a recent news article[Stolen Data Sale]: Facebook reported that 81,000 Facebook accounts were stolen under its watch, while simultaneously the hackers claimed that they have details from a total of 120 million Facebook accounts and are offering them for sale at 10 cents per account. They also published samples of private messages from those same 81,000 accounts in Facebook's damage tallies. In other words, the uncovered break-in directly against Facebook is only a tiny fraction of the cybercrime on our private data. At 10 cents a pop anyone can have your personal details like telephone numbers, email addresses, work, gender, religious affiliation and even the types of devices used to access the Facebook site. This offer of sale is good until way past your life expectancy. Nothing is forever except death and loss of privacy to the Internet.
Within the short span of 2 months while working on this blog, newer and even more shocking numbers have emerged at an ever alarming rate almost weekly. At the conclusion of writing this blog, the latest discovery on data breaches involving email address and/or passwords has reached a billion records[Collection No. 1], 1.16B to be exact.
Needless to say that there will be no GDBR-conforming privacy statements forthcoming from these dark enterprises. As long as our data is in the care of these giant centralized services, breaches on data are technologically inevitable and they will leave us without recourse. It is unlikely for governments to mandate as to what technical degree the collected data must be protected and how damages would be fairly compensated after breaches.
If you need more convincing, read up on the latest report [hacking 2018] for 2018. The latest wave of hacking has become even bigger, more sinister, and more widespread as companies that one wouldn't expect to be involved in the reported scandals like "Panera Bread" appeared as well. We'd venture to say that at first glance a bread and sandwich vendor is probably not known for their sophistication in providing privacy protection for your data, and yet Panera Bread has its customers' names, emails, physical addresses, birthdays, and the last four digits of their credit card number, all in plain text.
To escape from this web of entrapment, we need to get off the public social grid beyond the reach of their "free" offerings and instead sign up for burgeoning alternative "decentralized services" or "distributed trust network" if possible. In adopting these we don't lose much function, but probably will be temporarily inconvenienced. It requires a certain amount of initiative on our part and overcoming a not-so-steep learning curve. We must resist the allure of free and expedient services that have been proven unmistakably to cost us irreparable harm in the end.
I hope that by now you are convinced that the situation regarding your privacy is worse than you think. Ai-Fi.net is trying to offer proven alternatives for you to rebuild your social networks and Internet identities. The Ai-Fi.net infrastructure is not as performant, often costing fees, but guaranteed to rid of all predatory practices and to minimize your exposures to hacking.
Privacy and the Big Brother
Seeking privacy protection against unwarranted surveillance by the Big Brother is fairly easy to justify. Edward Snowden proclaims quite convincingly that "Arguing that you don't care about the right to privacy because you have nothing to hide is no different than saying you don't care about free speech because you have nothing to say." It doesn’t matter if you have "nothing to hide" or not. Privacy is a right granted to individuals that underpins the freedoms of expression, association and assembly; all of which are essential for a free, democratic society.
Preservation of and insistence on our privacy is also consistent with the Fifth Amendment. The Supreme Court of the United States, per curiam, states that "One of the Fifth Amendment's basic functions is to protect innocent men who otherwise might be ensnared by ambiguous circumstances. Truthful responses of an innocent witness, as well as those of a wrongdoer, may provide the government with incriminating evidence from the speaker's own mouth."[Supreme Court] We'd like to believe that our government will act in good faith as the benevolent guardian of our privacy and human right, but its track record in this regard is far from being perfect. We must take matters into our own hands in protecting our own innocence and not necessarily wrongdoing,and make sure our private data remain private away from any privy eyes.

According to experts' estimates, the data collected by NSA facility in Fort Meade alone has reached Zettabytes in 2015 in its 1.5 million square feet data center. That facility is expected to require 65 megawatts of electricity, costing at least $40 million per year of our tax dollars. In average it collects about 3 Terabytes of information per US citizen per year, more than the whole total of personal disk storage for most of us. We don't know what is being collected in these data centers; we certainly don't want any of those relevant to us personally to fall into the wrong hands.
Internet Privacy is an Oxymoron
Most of us are ignorant of the fact that Internet Privacy is an oxymoron. The uploading of information of any subject to Google or Facebook constitutes an act of publication for all intents and purposes. Once uploaded, it will take on an immortal life of its own. Realistically, after its escape from us, it can only get contaminated, polluted or distorted. Judging from those titillating "revenge porn", we can't safely upload anything to any single person, regardless how absolutely reliable he or she appears at the time. Potential misuse of our private data by Google or Facebook has the same effect of "revenge porn" magnified thousands of times. Expecting our personal data to stay private and under our control in someone else' custody is totally unrealistic. It also runs counter to the profit motivation of these enterprises who monopolize many of the Internet platforms in order to profit from the collected data. Once it enters into the bowels of the platform it is no longer private, by nature and by definition. No amount of GDPR and privacy-protecting regulations would help. It's far more practical in assuming that any digital asset lays hold on an eternal life independent from us.
Another confusion about privacy is how some of us draw the parallel between consigning our personal information to Google or Facebook and depositing our financial assets to banks. The push for privacy regulations such as GDBR and others is partially motivated by this unsound comparison. They hold the belief that privacy is also an "asset", which may be consigned to someone else and that act of consignment can be protected by government regulations. They lose sight of the fundamental difference between digital information and financial assets. Traditionally our trust in banks is based on the belief that we know how much money we last deposited or withdrawn from the bank. We receive a monthly statement summarizing our transactions in two simple columns of debit and credit. The money is either there or not there, intelligible and verifiable by elementary arithmetic on a few simple numbers, not mentioning the vast amount of government regulations and FDIC deposit insurance. The bank is allowed to reinvest our deposits, for which we expect to be compensated by the interest accrued at the publicly disclosed rate. As our financial assets are perfectly portable and fungible, we can always switch banks if their performance is not up to our expectation.
This level of protection by the banks and its ease of verification is plainly not attainable for the protection of our private data, for we are dealing with two vastly different beasts. When we "deposit" our private data with Facebook or Google, we clearly do not have the same degree of regulatory support for achieving the same comfort level as in banking. Our privacy asset is not formally transferred to Facebook or Google through the official act of writing a check or its equivalent (proof of ownership), except our agreeing to a long list of privacy statements most of us fail to read. This contract of transferring our personal data is executed only once at the time we first sign up for an all inclusive account. There is no monthly statement forthcoming and we are not informed about any transactions taking place on our data behind their closed doors.
Technically data privacy regulations are simply not enforceable without a similar mechanism like the one in the banking industry wherein the bank is obligated to provide to us a detailed account history based on which we the consumers are empowered to conduct a play by play auditing on our own private assets. Although the handling of the metadata regarding our bank accounts is also regulated, their score on privacy and security is much less stellar[Bank-Score]. Fortunately, the fungibility of money and the fact that banks are allowed to create money turn a financial organization into a giant "tumbler" of currencies, which makes us less exposed.
On the other hand, for our digital assets and their unauthorized transference, we are not given similar feedback loops for discovering what has happened to our private data or detection of wrongdoings. Even the definition of what constitutes "wrongdoings" is open to interpretation, in which we have very little say. This is also why those well publicized data breaches of large Internet companies are without exception all "confessions", and in the case of the Facebook/Cambridge Analytica scandal only through whistleblowing, without which we'd never learn about those disasters that will seriously impact our lives. (Trusting our private data to a "cloud service provider" or Dropbox has similar issues)
Safekeeping of Digital Assets Is Very Hard
Safekeeping of digital assets is a very hard technical problem, if there is any lesson to be drawn from the plights of the sad history of DRM (Digital Rights Management, or copyright protection for digital media). Banking is a great invention in human history that turns paper money into something virtual, for which we rely on the government for trust and arbitration in conducting financial transactions. For the billions of dollars invested in Bitcoin and blockchains, so far it has really only solved the simple problem of double spending for digital currency. It is done through a consensus-based immutable public ledger, which is inherently public, hence the notion of public blockchain for privacy is probably also an oxymoron. It is safe to say that privacy protection in terms of who is allowed to access what under which circumstances is outside the realm of our technical feasibility for a long time to come, if possible at all.
Information on us does not belong to us, but is only about us. New technology generates increased exposure of data about us that it couldn't have before. Privacy is not the opposite of sharing, but that of inappropriate sharing. Some would argue that inappropriate sharing has become the norm rather than the exception as the sharing in electronic form has become so blasé that it easily entraps inappropriate sharing. The solution is to diminish mindless exposure, to encourage confidentiality, and to offer people ways to be hidden from such inappropriate exposure.
Recent Alexa eavesdropping scandal demonstrate several things:
- Amazon records a huge amount of highly personal data on us through Alexa.
- It is very hard, even with the unfathomable resources of Amazon, to safekeep those collected data correctly and competently.

These are scary facts. The defending of its failure of protecting our data is quite comical:
xxxxxxxxxxEcho woke up due to a word in the background conversation sounding like “Alexa.” Then, the subsequent conversation was heard as a “send message” request. At which point, Alexa said out loud “To whom?” At which point, the background conversation was interpreted as a name in the customer's contact list. Alexa then asked out loud, “[contact name], right?” Alexa then interpreted background conversation as “right”. As unlikely as this string of events is, we are evaluating options to make this case even less likely.”
I have counted 6 consecutive "loud" and "unlikely" errors in a row. Note that this mishap is committed by a company owning 44% of US ecommerce sales. Obviously Amazon has a profit design in mind for those collected data, which will be repackaged and transacted in many downstream settlements. The question is how well we can trust its competence in protecting our data. Given the low premium placed on our privacy data and the negligible cost penalty ratio on mishandling the collected data, we just have to agree with Edward Snowden that EU privacy overhaul, GDPR specifically, misplaces the problem. “The problem isn’t data protection, the problem is data collection,” Snowden said. “Regulation and protection of data presumes that the collection of data in the first place was proper, that it is appropriate, that it doesn’t represent a threat or a danger.”
Brave's BAT (Basic Attention Tokens)
It is indeed more democratic in the sense that voting through BAT is anonymous but still gives feedback to the products that solicit inputs. The merchants obviously are no longer capable of pinpointing at a specific customer and providing fully targeted ads. However, it does thwart Google or Facebook from spying on unsuspecting "dumb fucks".
The flip side of BAT is the fact that Google and Facebook would now need to charge us for the services they render if ever after they lost the bloodline of their brand of surveillance capitalism.
Life After Google: Ten Laws

Considering its tight grip on the Internet, is there life after Google? Some optimists think the blockchain-based "cryptocosm" is just one such possibility that may help us bypass Google and deliver the next customer-centric decentralized Internet. Writer and visionary George Gilder[Gilder] outlines the downfall of Google in Ten Laws and their evolutionary counterparts that will motivate us to construct the coming Cryptocosm world as follows:
| GOOGLE'S LAWS | CRYPTOCOSM LAWS | |
|---|---|---|
| 1 | Communication first. Give them free stuff. | Security first. Nothing is free. |
| 2 | It's best to do one thing really, really well. (Be world champion in AI-based answers.) | Create a secure foundation for customers to do many things really really well. Centralization is not safe. |
| 3 | Fast is better than slow. | Recognize the primacy of human scale over computer gigahertz. Safety last. Only humans matter. |
| 4 | Democracy on the web works. Google is a hierarchy. We rule! | Majority rule is 51% attack - a catastrophe. The blockchain is a heterarchy. |
| 5 | You don't need to be at your desk to need an answer. | If your phone is smart, the least it can do is suppress ads. Net ad click-thru rate is %0.03 anyway. |
| 6 | You can make money without doing evil. | Real money is good. Money is a measuring stick, not a magic wand for central banks. Nothing is free. |
| 7 | There is always more information out there, and we can get it by giving our services away for FREE. | Information should be owned by its creators, not by its distributors. |
| 8 | The need for information crosses all borders. We are citizens of the world and Google Translate gives us a worldwide edge. | The cryptocosm respects the borders of your computer. Security is the property of the user and device, not the network. |
| 9 | Private keys are held by individual human beings, not by governments or Google. | You can conduct transactions without committing personal data to an insecure Internet. |
| 10 | Great just isn't good enough. | We provide an architecture of security and time-stamped factuality which enables our customers to be great. |
The Million Dollar Question is:

"Will Blockchain disrupt Google, Apple, Amazon, and Facebook?"
The Google system of the world is broken in 10 different ways. The Cryptocosm disperses the clouds and remedies the disorders of the Google system of the world with "sky computing". This brave new Cryptocosm will be cleansed from the illusions of free services, explicit in its cost proposition, spending real money without surrendering personal data, heterarchical and not hierarchical, and most importantly building security as its first priority right from the start.
The security model of Ai-Fi.net is consistent with this view of the new Cryptocosm. Nevertheless, before venturing out to the wild jungle of the Internet we must first root ourselves firmly with a secure personal domain that protects our private possessions, including our identities, profiles, social roles, community contacts, purchasing history and spending preferences. In other words, security first.
The war between the traditional "free" services and the immutable public-ledger based Cryptocosm will take decades to duke it out. Both camps establish themselves firmly in the public cloud, either not paying enough attention to the advent of IoT or not being able to offer compelling conceptual model to the satisfaction of the consumers. We at Ai-Fi.net have a different world view:
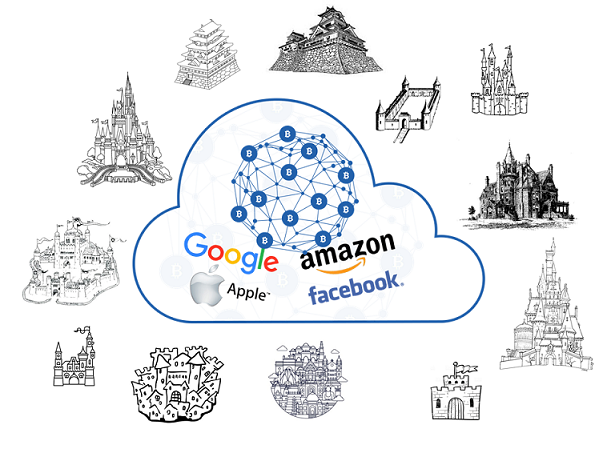
We believe we must take matters into our own hands before the decentralization disruption proves itself and takes hold, regardless if it is based on blockchain or not. We must build our own castles. With Ai-Fi.net, each individual castle is in an Ai-Fi private domain, segregated from all others and secured against unwanted scrutiny through safe placement of all valuable assets behind impenetrable walls. Unless they are to be shared, individual IoT objects are largely private and protected behind strong fortifications. This is our answer to the law of "Safety First", the privacy proposition sorely missing in the debate in our opinion.
The rest of this article will detail how we at Ai-Fi.net can contribute in rebuilding this brave new Cryptocosm after Google as the security infrastructure underlying all decentralized transactions.
PART II: Cyber Realities and Attack Surfaces
A Survival Optimization System (SOS) has been proposed to account for the strategies that humans and other animals use to defend against recurring and novel threats:
xxxxxxxxxxThe SOS attempts to merge ecological models that define a repertoire of contextually relevant threat induced survival behaviors with contemporary approaches to human affective science. We first propose that the goal of the nervous system is to reduce surprise and optimize actions by (i) predicting the sensory landscape by simulating possible encounters with threat and selecting the appropriate pre-encounter action and (ii) prevention strategies in which the organism manufactures safe environments. When a potential threat is encountered the (iii) threat orienting system is engaged to determine whether the organism ignores the stimulus or switches into a process of (iv) threat assessment, where the organism monitors the stimulus, weighs the threat value, predicts the actions of the threat, searches for safety, and guides behavioral actions crucial to directed escape. When under imminent attack, (v) defensive systems evoke fast reflexive indirect escape behaviors (i.e., fight or flight). This cascade of responses to threats of increasing magnitude are underwritten by an interconnected neural architecture that extends from cortical and hippocampal circuits, to attention, action and threat systems including the amygdala, striatum, and hard-wired defensive systems in the midbrain.
Those species with greater capacity to learn new skills that enhance the ability to avoid predators will pass on their genes and avoidance skills. However, for modern humans living in the Internet ecosystem, this SOS system is no longer adequate or even useful, as the technological advances outstrip our evolutionary time by a huge margin. Our efforts in avoiding malicious cyber predators attacking with virus infection, worm contagion, phishing traps, identity theft, fake WAP, keyloggers, etc., have become highly strenuous mental exercises without the visceral warnings endowed with evolutionary sophistication we'd have preferred. We have become easy targets largely ill-prepared for this onslaught of attacks.
The root source of all the cyber threats comes from the ever expanding cyber world we found ourselves in. Regardless whether you subscribe to the notion of "Singularity" or not, the line between the physical and the virtual is increasingly blurred with the latter ever encroaching upon our private lives. The "Augmented Reality" will bring us tremendous benefits, but not without potentially fatal risks.
Cyber security and protection are all about "attack surfaces". The wider the exposure or the exposed exterior, the larger the attack surfaces vulnerable to exploitation. The following picture makes excellent war propaganda material:

However, it doesn't communicate the fact that our adversaries will equip themselves with the same and the attack surfaces of this augmented reality are left without proper study and certainly quite fragile. The "Pokemon Go Attack" can pop into our augmented reality from anywhere at any time, undetectable by our senses if without the help of the intelligent devices:

Granted that both the augmented reality and the virtual reality are in their embryonic stage and unpredictable as to how far they'd take us (which is exactly the issue here) currently, the real and material world we live in is evidently expanding at breakneck speed along these new imaginary axes. Our intelligent devices used to include only personal computers and dial-up phones, physically tethered to their wires strung through the walls. With the advent of IoT and other wireless smart technologies, our tangible world has been promptly filled with the following:
- smartphones and the ever smarter apps
- fitbits, fitness trackers, smart watches, and other smart wearables
- driverless cars
- drones
- robots (of various functions and utilities)
- ultrasonic waves
The problem is that we are only equipped to live in the circumference of being, in the perimeter of senses at the evolutionary time scale, and thus we will unavoidably fall victim to the deep, dark, wide-ranging, unsuspecting attacks around us in the rapidly inflating cyber space. We constantly attempt to understand ourselves and others in terms of established worldly relationships and social norms. Unfortunately we can't make these new species like Facebook, Google, Apple, Amazon, and not the least hackers, abide by the same time-honored rules that have been very painstakingly hammered into us by evolution. We are very poorly prepared for this brave new cyber world. We are all pretty much "dumb fucks" trapped in our stone-age frame, observed by Mark Zuckerberg when he was only a 19-year-old.
As uncovered by Charles Darwin that organisms unable to adapt to the demands of their environment will fail to pass on their genes and consequently fall as casualties in the “war of nature”, we humans are clearly in danger of losing this self-inflicted cyber wars.
Part III: Private Security Through Ai-Fi
TBD.
Part IV: Ai-Fi Security Framework
Introduction
To adopt Ai-Fi.net, the conceptual model of your private world is depicted as follows:
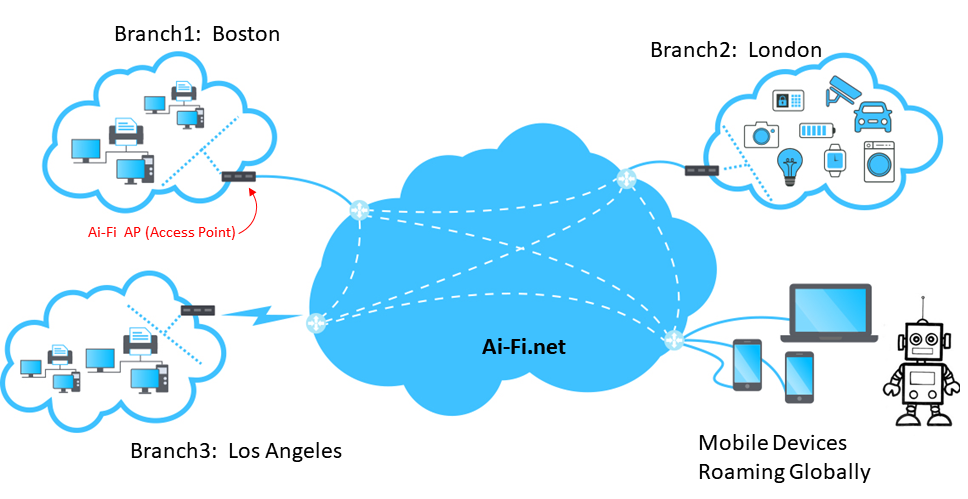
It is more than a simple App and appears daunting to configure. However, it is really not that bad. It involves only two functional modules, each may have variations if it is usable on multiple hardware platforms:
- The Account App: This is the software to install on your cell phones, the root of your account (your private key) and where the master copy of the configuration of your domain is stored.
- AP (Access Point) App: This is to be installed on all the Access Points, as depicted in the above diagram as the gateway routers functioning as the on-ramps into the Ai-Fi.net for secure connectivity. Each of your branch sub-cloud needs at least one of these Ai-Fi routers. Note that if a device such as a robot is to be a roaming Ai-Fi object, it needs the AP App to turn it into a sub-cloud all by itself (COO, or Cloud Of One) with a single IP address, roaming and connecting in and out of the Ai-Fi cloud freely.
Pseudonymous Ai-Fi ID
Creating Your Ai-Fi Account
Most Ai-Fi.net functions are only available to members with an Ai-Fi account. An Ai-Fi account is created through the Account App, physically hosted on either the Android or Apple cell phones. When first signing up, the account owner picks their own unique Ai-Fi account identifier. Once established, the Ai-Fi account owner performs their Ai-Fi-related functions pseudonymously, identifiable only through their Account ID of their choosing without the need to associate it with any of the owner's other worldly identities such as their cell phones or email addresses.
An Ai-Fi account is protected by two independent verification factors:
- Each of the participants has a pair of keys based on the same Elliptic curve cryptography as Bitcoin. It is a public-key cryptography protocol where there is one private key which is kept as a secret by the owner and one public key which is stored with Ai-Fi.net as part of the account profile of limited content. The sign-up device must be an iPhone or an Android phone where the private key is physically stored and the signing up to Ai-Fi.net was originally made. Ai-Fi.net makes no use of its associated phone numbers.
- In addition to the account ID, a second password-based factor is required for account authentication, which is verified at log-in time through the SRP protocol executed within a SSL tunnel connecting to the Ai-Fi.net authentication server. Ai-Fi.net has only a cryptographic verifier derived from the password but not the password itself and therefore is immune to fiasco reported in the latest loss of passwords by Instagram[password].
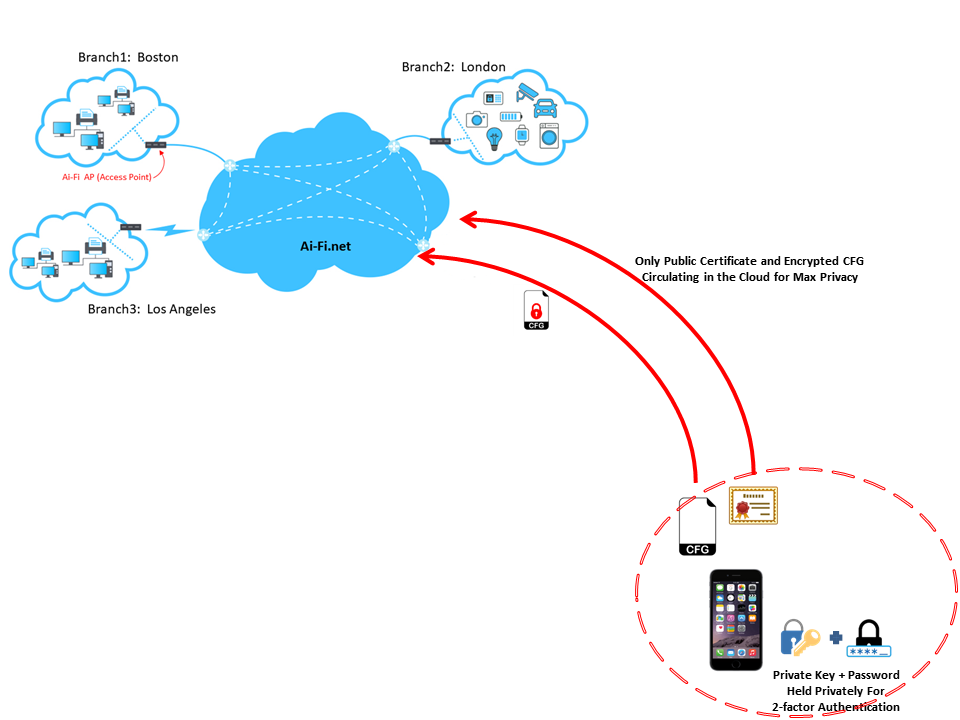
Both factors are required to log in. The private key is stored locally in the Ai-Fi client app's sandbox with the usual access control enforced by both iPhone and Android. The Ai-Fi account holder must take good care of their private key (on their personal mobile phone) and password. An account is recoverable after losing either one of the log-in factors only by registering with Ai-Fi.net with some recovering credentials such as email account or cell phone number. The account owner likely loses the pseudonymity if this recovery option is selected. This is also why Ai-Fi.net doesn't support Identity Federation natively.
Note that the Ai-Fi account key pair adopts the same scheme as in the Bitcoin or many other Blockchain based distributed applications, which are used to protect billions of dollars of Bitcoin transactions. It is further strengthened with a second factor offering zero-knowledge password protection.
Note that the origin of the domain configuration file is also stored in the account owner's mobile phone, protected by the same sandbox and encryption facility included in the standard function set provided by these modern phones. The content of the configuration file is only partially known to Ai-Fi.net, as much as needed for Ai-Fi.net to serve its secure connectivity functions. For instance, the ACL (Access Control List) for various domain branches is not managed by the domain itself without being kept in the Ai-Fi cloud. Again, the account owner must take good care of their personal phones or suffer the consequences of recreating the complete account-related information on their original phones.
Due to the very limited amount of information retained by us which might be used for profiling the individual behind an Ai-Fi account, the only likely subpoena to us would be about an account based on its pseudonymous account ID. Other domain components are encrypted and not exposed to any third parties, which are therefore not discoverable even when the third party is in possession of the domain owner's mobile phone. In other words, the domain information is only indexed through its owner's account ID.
The Zero-Knowledge Doctrine
- Ai-Fi.net acquires only enough information to maintain the secure, private and end-to-end encrypted connectivity for domain components.
- Ai-Fi.net retrieves information from and operates on a domain based on configuration information only as long as necessary to carry out the functions delegated to the Ai-Fi service.
- Ai-Fi.net does not record or store any historical data outside the user domain regarding the transactions performed by a particular domain.
Without subscribing to "surveillance capitalism" it is quite straightforward for Ai-Fi.net to attain zero-knowledge proof for its network services, collecting minimal amount of meta-data regarding its subscribers. It also makes it resistant to dictionary attacks and offers a zero-knowledge password verification approach immune to password theft.
How Much Does Ai-Fi.net Collect about a Domain
Known to Ai-Fi.net
- The pseudonymous owner/administrator of a domain and the verifier for his two log-in authentication factors
- The public key for identifying domain branches
- The registration information required for a domain branch to become online
- If delegated to Ai-Fi.net, proxied public IP addresses for privately managed home-servers or web sites as part of the DAP (Domain Access Proxy) service
Not Known to Ai-Fi.net
- the Private key and password of an Ai-Fi account (zero-knowledge)
- ACL (Access Control List for remote accesses) for domain branches
- All network traffic and application transactions between Ai-Fi APs (Access Points) and their protected branches
- All network data between devices embedded within a branch behind its Access Points
Meta-Data and You
Ai-Fi.net maintains only minimally required data for connecting domain branches. All domain traffic is private and segregated from all other domains. Ai-Fi.net does NOT keep historical records or logs of any Ai-Fi transactions such as:
- Time and location of the Ai-Fi account log-in and transactions performed
- The real-time dynamic registration request by a domain branch for entering into the Ai-Fi.net. This includes the mobile Access Point logging in as a "cloud of one" to effect remote access.
Note that in most cases when a private domain has sufficient network resources, Ai-Fi.net only provides limited support covering the initial log-in signaling protocols. Once connectivity between domain branches is established, Ai-Fi.net involves very little in their interaction among branches. There is very limited permanent meta-data for Ai-Fi.net to record. The general principle is that Ai-Fi.net is designed with the minimum knowledge of domains necessary for it to function, and where domain configuration knowledge is required it gathers the minimum necessary amount of information and retains it for the shortest time possible.
Security by Design
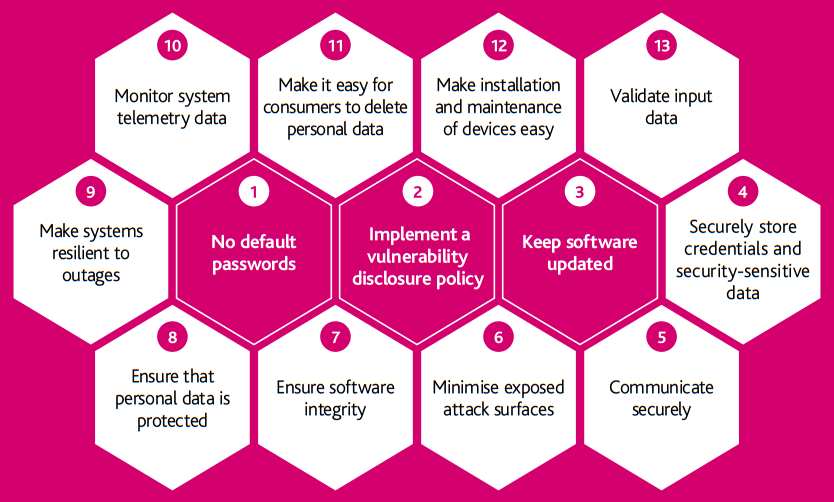
The accompanying "Consumer Guidance for Smart Devices in the Home" [Crown Security]
Multi-Tenant Configuration Cache
Each Ai-Fi domain is accessed and managed by its owning Ai-Fi account. Ai-Fi.net is involved only when necessary for the requested operations. Both the private key and the original copy of the domain configuration are physically stored at where the original account was created on, which currently must be either an iOS phone or an Android phone. Ai-Fi.net trusts the sandbox, the secure container (Keychain), the TPM (Trusted Platform Module) and other security mechanisms built into these modern intelligent mobile phones, and the fact that they are physically in the possession of their rightful owner at all times.
The domain configuration is cached in the Ai-Fi cloud. Ai-Fi.net is able to read its content only partially, just enough to allow for the delegated functions. The access of the domain configuration is strictly controlled on the need to know basis with the file encrypted jointly by the owning account, the participating APs (Access Points) and Ai-Fi.net cloud.
Hierarchy of Ownership
The domain and its branches are solely owned by the original Ai-Account that created them. The domain owner is required to be present and involved in the creation of other secondary domain components, such as branches, remote access account list, DAP (Domain Access Proxy) specification, et cetera. This is why the original Ai-Fi account must be created on a mobile phone which provides protected storage for its associated private key. The ability of the mobile phone to read a QR code or 2d Barcode code also improves the ease of use considerably. A second log-in password provides the second factor in securing the device and protecting against loss of the mobile phones. Note that the phone number of the mobile handset is purposely ruled out from this authentication process and not made known to Ai-Fi.net so that the pseudonymity of the account is guaranteed. This is verifiable as the client software is completely open-sourced and all the APIs for account creation is published to the community.
An Ai-Fi account must be authenticated before getting admitted to the Ai-Fi.net for other useful functions. End users have full possession and control of their data, including the complete source code that executes on the clients. All domain operations on the data plane are embodied in open sources and are verifiably secure.
Remedy for Losing Your Ai-Fi Account Identification Cellphone
Since your Wi-Fi account credentials are based on the key store hardware on your cell phones, which are typically hardware protected against tampering and extraction. In other words, once you've burned your private key onto your cellphone for establishing your Ai-Fi account identity, you must be in possession of it in order to authenticate yourself to Ai-Fi.net. The consequence of this rigorous authentication requirement is the loss of recoverability, should you lose your cell phone.
As a matter of design, your Ai-Fi assets are protected through:
- Your 2-factor account credentials
- The configuration file owned by your account
- The physical access to those devices specified by the configuration file
Item 2 may be backed up to lessen the stress of losing your cell phone. It is assumed that you are among the precious few that have physical access to your domain, branches, and devices embedded within. In the event of losing your cellphone, your only option is to create a new Ai-Fi account, re-attach item 2 to the new account, and adopt the same AP names for all your branches so those APs may be re-claimed one by one.
Ai-Fi Support for Internet Browsing and Tor
The security mechanism built into Ai-Fi.net is mainly to protect inter-branch traffic within a private domain. Intra-domain traffic is able to travel between branches freely and securely. On the other hand, non intra-domain Internet traffic is usually filtered out locally and "split" off directly at their first Ai-Fi relay. Those traffic can take advantage of the routing capability of those Ai-Fi relay networks and get routed to a specific relay before injecting onto the Internet. This detour function may achieve two goals:
- Improving the speed/latency in reaching the Internet destination by taking advantage of the network resources of Ai-Fi.net.
- Bypassing the possible obstruction or privacy invasion at the initiating Access Point (e.g. censorship, ISP post net neutrality rules, etc.)
Specifically, for anonymous Tor browsing, the suggested approach for Tor censorship avoidance is to adopt the Pluggable Transports and select the appropriate Tor Bridge Relays, which doesn't always work. Ai-Fi support for substitute routing path provides a secure alternative.
Branch Start-Up and Authentication
TBD
Part V: Extending The TLS
Asynchronous Session and Future Secrecy
The TLS gold standard is session based. The most popular application of TLS is the HTTPS schema during web browsing.
TLS has a deployment requirement that both ends of the session must be online while the negotiation of encryption keys is conducted. This online requirement and others are not always satisfied in many application scenarios:
- Not all sessions are TCP based: This issue is addressed by DTLS or other encryption schemes that apply to UDP.
- A device may attempt to establish the session key asynchronously without the other party being online. This is the typical scenario for Email, the sending or receiving of which can't assume the presence status of the other party.
- Some sessions tend to be extremely long-lived (perhaps even years long). For instance, the current power target for some IoT sensors is to last for 10 years, during which time there is a very limited number of sessions for connecting to its command controllers.
As the gold standard, TLS lays out the minimal requirement for session connectivity, which must not be weakened or altered without clear justification[Bluetooth]. Ai-Fi.net supplements it with advanced cryptographic re-key or ratcheting[Ratcheting] for those less conventional scenarios described above beyond the traditional web browsing applications. The following security properties are both offered:
- Forward Secrecy: Unlike PGP, TLS uses ephemeral key exchanges for each session. Otherwise a network adversary who records (potentially years of) ciphertext traffic can later decrypt all of it if they manage to later compromise the one key that was used. With this property, there is no key to compromise in the future, so any recorded ciphertext should remain private.
- Future Secrecy: The session is self-healing. If, for whatever reason, any individual ephemeral key is compromised or otherwise found to be weak at any time, the ratchet (re-key) will heal itself.
A greatly simplified mechanism of double-ratcheting is pictured below:
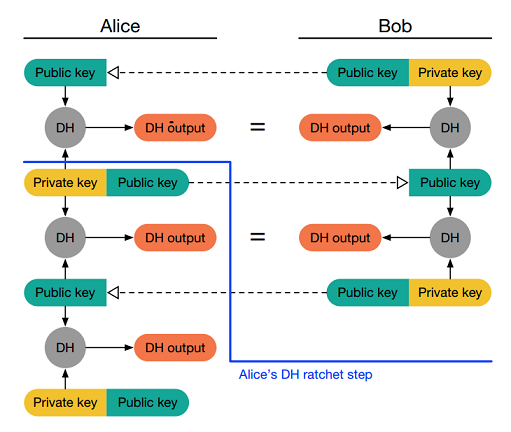
As diagrammed, the Diffie-Hellman ephemeral keys are re-generated every time a new message is exchanged (not considering lost or out-of-order messages for now). In other words, in addition to the per session ephemeral keys, double-ratcheting changes encryption keys per round of message exchanges, which literally stops any compromise of keys in its track.
Ai-Fi SecureEmail
Both S/MIME and OpenPGP-based secure emails are broken. Ai-Fi.net offers a new implementation, taking advantage of its unique architecture to facilitate the end-to-end encryption with fresh ephemeral session keys based on "pre-keys". See our write-up on Ai-Fi SecureEmail for details.
References
^[Alexa Scandal]Here’s Amazon’s explanation for the Alexa eavesdropping scandal
^[Collection No. 1] 1/2019 New Massive Security Breach Exposes Damn Near Everyone’s Everything
^[Composite Images] 1/2018 How an A.I. ‘Cat-and-Mouse Game’ Generates Believable Fake Photos
^[Crown Security] 10/2018 IoT firms sign up to UK security code of practice
^[Data Breaches] 9/2018 The 17 biggest data breaches of the 21st century
^[FacebookShared] 12/2018 Facebook Used People’s Data to Favor Certain Partners and Punish Rivals
^[Facial Recognition] 8/2011 Google's facial-recognition technology used to identify students and SSN
^[FTC-new] 3/2012 The Philosopher Whose Fingerprints Are All Over the FTC's New Approach to Privacy
^[Gilder] 2/2018 Why Technology Prophet George Gilder Predicts Big Tech's Disruption
^[hacking 2018] 12/2018 How our data got hacked, scandalized, and abused in 2018
^[loopholes] 8/2017 Five loopholes in the GDPR
^[password] 11/2018 Instagram bug inadvertently exposed some users' passwords
^[PhotoAnalysis]2015 Portrait of a Privacy Invasion: Detecting Relationships Through Large-scale Photo Analysis
^[Spider Lucas] Lucas the Spider is an animated character appearing in a series of YouTube videos. Created by animator Joshua Slice and voiced by Slice's nephew, Lucas the Spider is based on a jumping spider.
^[Stolen Data Sale] Private messages stolen from 81,000 Facebook accounts are up for sale
^[Supreme Court] 3/2001 Ohio v. Matthew Reiner
^[Bank Score] 9/2019 Deep Dive: How Do Banks Score on Privacy and Security?